最近,通用人工智能公司 VAST 完成了 A+ 及 A++ 两轮融资,合计近 2 亿美元。本轮融资由渶策资本、国寿长三角科创基金领投,深圳市人工智能终端产业基金、上海半导体产投、深创投、元生资本等产业与财务资本跟投。
伴随这笔融资一同亮相的,还有他们首次对外披露的世界模型项目:Project Eden(代号:伊甸园)。

这笔融资和新项目 demo 的发布,让原本就热闹的世界模型赛道,多了一个挺有意思的变量。
最近一年 AI 的进展快得让人有些喘不过气。前段时间,一位游戏公司老板对我说,行业现在对 AI 进展的反应很像收到地震预警:警报一响,你总得跑下楼看一眼。多数时候是虚惊一场,但你也不敢原地不动,因为说不定哪一次真就变天了。
世界模型给人的感受尤其如此。今年年初,谷歌 DeepMind 推出 Genie 3 后,资本市场的情绪被瞬间点燃,Unity 创下自 2022 年以来最惨的单日跌幅,Take-Two、Roblox 等游戏股也全线跳水。但业内很快反应过来,这更像是一次被 AI 叙事点燃的过激反应,Unity 的 CEO Matthew Bromberg 则点出了更根本的局限:这类世界模型的输出是概率性的、非确定性的。
从游戏行业的视角来看,Genie 3 的技术路线有某种天然缺陷。它能生成一段直观上高度逼真画面的视频,却撑不起一个真正能玩、能反复进入、甚至能多人联机的游戏世界。
相较而言,今天 VAST 推出自己首款世界模型项目 Project Eden 倒是让我眼前一亮。在世界模型之前,VAST 最为人熟知的是 Tripo 系列 AI 3D 生成模型,干的是“造万物”的活。在 VAST 的叙事里,从造万物走到造世界,是水到渠成的下一步。
“AI 3D 资产和世界模型,本来就是两轮驱动。” VAST 首席科学家曹炎培告诉我,他们从第一天开始的目标就是打造下一代可交互的 UGC 内容平台,AI 3D 解决的是“造万物”的极速与低门槛,而世界模型则是为了解决“造世界”的系统性推演,“这是技术演进的延长线,也是水到渠成的下一步。”
当绝大多数人都在谷歌 Genie 那种“动作条件视频生成”和 World Labs Marble 那种“静态 3D 场景生成”之间二选一时,Project Eden 走出了第三条路:把“世界状态的演化”和“画面的视觉呈现”在架构上原生解耦。
这套独特的架构,自然解锁了此前其他世界模型无法跨过的三道天堑:环境的长程持久、场景的自由复用,以及多人的并发交互。
01
被高估的两种路线,与 VAST 的独特解法
要看懂 VAST 这条路,我们先来看看此前的世界模型为什么很难在游戏行业内真正用起来。
生成式 AI 领域的知名科学家黄勋曾提出过区分“视频生成”与“真正的世界模型”的五条属性。一个真正的世界模型,需要在满足因果性、交互性的基础上,尽可能达到更好的持久性、实时性与物理准确性。拿这把尺子去量,我们会发现,目前在游戏行业被高度关注的两大主流路线,在面对生产级游戏的严苛标准时,都各自遇到了难以跨越的局限。
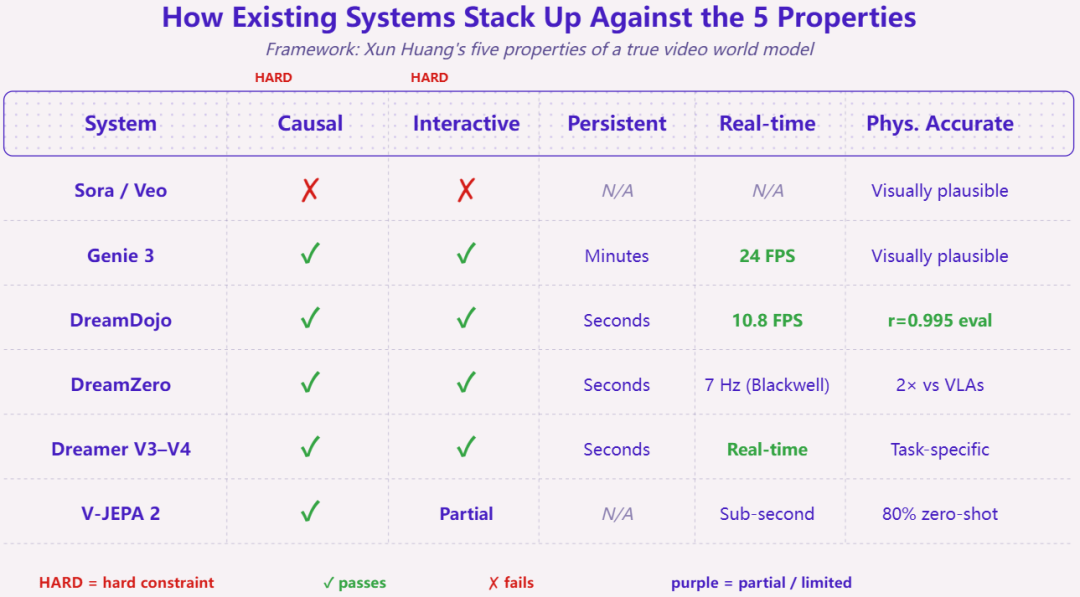
第一种是进展最快、也最瞩目的“视频生成派”,以 Genie 为代表。这种路线本质上是在做 2D 像素的自回归预测,看着已有的画面去猜下一帧的每个像素该长什么样。曹炎培直言,将这种端到端视频生成等同于世界模型是一个误区:“端到端视频模型所有的状态都与当前视角强绑定。一旦相机镜头转出墙角,模型就只能凭着上下文重新脑补,根本无法提供游戏所需的‘长程持久性’。”
视频生成派把两件量级完全不同的任务强行捆绑在了一起:一个是预测世界接下来会发生什么,这个信息其实相对较“轻”;另一个是把每一个像素都精确地画出来,这个信息极其“重”。这种轻重不分的底层逻辑,让它在实际应用中很像一个没有剧本的漫画家,必须一边画一边现编剧情,不仅导致画面在视角切换时容易发生漂移或畸变,也让多人联机交互变得极难实现。
第二种则是以 World Labs 的 Marble 为代表的“静态重建派”。这一派倡导的“空间智能”确实切中了空间几何的稳定性,能高速重建出可以游览的三维空间。但它的局限在于,它目前只有空间,没有时间。它缺乏在时间轴上推演状态的能力,造出来的是一个凝固的环境。用黄勋的标准来看,这种方案在“交互性”上有硬伤,它更像是一个精美的 3D 标本,漂亮,但无法演化。
既然视频生成派缺了“剧本”,静态重建派缺了“演变”,那么 Project Eden 的解法就是:把剧本和绘画的工作分开来做(解耦)。这使得它成为目前行业内首个允许对世界状态进行自主维护、并施加确定性控制的世界模型。
02
把状态和画面拆开:用 AI 造一台引擎
VAST 给出的技术范式,一句话概括,就是把“状态维护与预测”和“画面渲染与呈现”从架构上拆开来做。
这句话乍听起来很难理解。但对游戏人来说,这个思路其实非常眼熟:它很像游戏引擎的工作方式。引擎内存里维护着一份“世界数据库”,记录着所有物体的位置、属性和状态;当摄像机移动时,渲染管线再根据视角,把视野内的场景实时绘制成画面。状态归状态,画面归画面,两件事是分开的。
VAST 想做的,就是用 AI 在神经网络里造出这样一台引擎。这是一块非常难啃的骨头:状态怎么在神经网络里表达、用什么样的网络架构、如何获取并扩增海量的数据,在曹炎培看来,这其实是一个巨大的鸿沟。
为了跨越这个鸿沟,Project Eden 创新性地采用了解耦式的三层技术架构。
其底层是结构化状态层,统一维护场景的几何结构、物体属性与事件逻辑,全权负责客观状态的推演。
中间的条件接口层则作为状态与渲染的转换枢纽,依据不同视角将 3D 状态转化为约束条件,从根源上保障跨镜头的物理一致性。
最上层则是生成式渲染层,依托底层的客观状态与中间层的约束,按需实时渲染出精细化的视觉画面,补足动态细节。
曹炎培用 demo 中的“消防员灭火”的场景展现了 Project Eden 的工作逻辑:用户用一段提示词描述厨房、消防员和火灾的初始条件,这段描述会被直接转化为底层的隐式状态。当玩家控制消防员移动并按下灭火键时,喷了多少粉末、火有没有被浇灭,这些判定全部在底层的状态层中完成推演。哪怕此刻一帧画面都还没画出来,这个世界在底层已经“真的”在按某种物理逻辑运转了。
而在这之上的渲染层,则像是一个随时待命的写实画家,只需依据当前的底层状态,结合玩家此刻选定的任意视角,把那一帧画面渲染出来。在传统图形学中极难表现的气体扩散、火苗舔舐墙壁等流体运动,在这套架构里反而能被渲染层非常自然地模拟出来。
这种将状态与画面拆开的解耦设计,不仅在技术上更加优雅,也顺理成章地解决了游戏开发者最头疼的几个核心痛点。
首先是“一致性”的回归。因为世界状态是独立于视角被维护的,你转个身走开再转回来,那棵树还好端端地待在底层的数据库里,等着被重新渲染。视频生成派那种一转身物体就漂移、场景就畸变的老毛病,在这里从根源上被解决了。
其次是赋予了场景“可被反复利用”的生命力。既然世界状态是独立存在、可读可写的,那么玩家在场景里做过的事就会被真实地留下来。一个玩家砸坏了桌子,这个改动会实时写回底层状态,之后另一个玩家进入同一个场景,看到的会是破坏后的结果,而不是一个被重新脑补、完好如初的房间。
沿着这个逻辑,多人交互的难题也迎刃而解。因为底层摆着一份独立于视角的统一世界状态,多个玩家就可以共享这份状态,再各自渲染各自的视角。玩家与玩家、玩家与 NPC 之间,才谈得上真正的实时互动。这与今天多人游戏的“服务器-客户端”架构异曲同工。
此外,这种模式还带来了一个商业上的巨大优势,即算力成本的急剧下降。在解耦架构下,渲染层比较吃算力,而底层的状态推演是非常轻量的高维计算。这直接解决了视频生成路线“要为每个视角、每个在线用户单独从像素级生成画面,导致算力开销随人数呈指数级暴涨”的隐忧。
当然,这套架构目前依然处于比较早期的阶段。但在 Project Eden 的 demo 中,我们能看到它试图一步步啃下硬骨头:长时间一致的环境漫游、多玩家实时互动,以及一些确定性的机制判定。
03
临界点到来之前,它能在游戏开发里做什么?
看到这里,难免让人倒吸一口凉气,等这个技术真正成熟,做游戏会不会不需要引擎了?
曹炎培告诉我,世界模型真正去替代游戏引擎,是一个非常长期、困难诸多的目标。只有当世界模型推演状态转移的计算效率、稳定性和可控性,彻底越过了实时响应的阈值,这种突变才会发生。
而在眼下,与其争论哪一天会变天,不如看看在临界点到来之前,这套技术能够怎样走进游戏开发流程。
在当下的起步阶段,我们可以将这套解耦架构拆开,单点接入现有的游戏管线。比如后端的渲染模型可以朝“生成式渲染”的方向使用。设想你是个策划,没有很强的美术和程序能力,你可以先用非常简易的Blockout(灰模)把空间和关卡结构搭出来,验证玩法。然后,让渲染模型把这套灰扑扑的灰模,渲染成你想要的任意画风。
打光、精细资产制作、甚至复杂的物理现象呈现,都交给模型在后阶段去补。
对中小团队来说,这几乎等于把昂贵的美术工业化成本,缩减为一次模型调用。画风会从立项前就必须锁死的成本硬约束,变成上线前可以一键切换的“开关”。
与此同时,前端的状态预测模型则可以被单独拎出来,作为“智能状态机”使用,替开发者省掉大量写脚本、做状态机的重复劳动。比如门被踢一脚要转多少度、转多快、是否会反弹回来撞到人,动画或状态机可以直接由模型推演输出,而不必由程序员一行行代码去规定。
随着技术的成熟,更进一步的阶段则是让世界模型局部接管“动态与开放场景”。在这一阶段,游戏主体仍由传统代码驱动,但在一些特别开放、复杂、同时又不那么需要强确定性的动态场景里,可以调用世界模型来进行离线或小范围的推演。
例如,一场随机风暴对场景造成的破坏,或者大量 NPC 之间自发的交互行为。把确定性要求高的部分留给传统代码,把开放、随机、难以穷举的动态部分交给模型,是现阶段最舒服的切入口。
而只有在越过临界点之后,才会迎来整体替代硬编码的终局。
“我们希望用一个更通用、更低门槛的神经网络,去替代这些需要硬编码的逻辑和物理定义。”曹炎培说,理想状态下,未来所有基于代码逐一指定的繁琐逻辑,都将变成基于大模型的数据驱动推演,开发的门槛和效率将发生质的飞跃。
不过,世界模型和传统引擎的关系未必是一场你死我活的替代。正如 Epic 创始人 Tim Sweeney 曾给出的中肯判断:未来我们会看到“以引擎为中心的 AI”和“以世界模型为中心的 AI”不断相互追赶、融合,直到某一天两者结合在一起。
VAST 正在做的,正是把“以世界模型为中心”这条路尽可能往前蹚,而临界点到来之前的每一步,都能为游戏行业递上一份实实在在的工具箱。
结尾
世界模型要走向真正的技术完善与工业落地,依然需要一个渐进的过程。在计算效率、物理规则的绝对精确性以及大范围场景推演的稳定性上,神经网络引擎还有不少技术阶梯要跨越。
不过,支撑这台引擎运转的 3D 资产,正在变得越来越充沛。作为 VAST 的核心业务,其自研的 Tripo 系列 3D 大模型在过去一段时间经历了快速迭代,今年 3 月上线的 Tripo H3.1 和 Tripo P1.0 模型,在几何精度和生成速度上都走向了工业级可用。
近期,他们还在 Tripo Studio 上线了 8K AI 贴图算法,将原本需要数天的手工绘制或扫描流程压缩至 2 分钟以内,并推出了支持三档颗粒度控制的“智能部件分割 V2”,让生成的 3D 资产能自动分件并直接进入下游管线。
此外,VAST 也在通过开源来推进行业共建,目前已累计对外开源了超 30 个项目,包括与清华、港大等高校联合开源的 TripoSplat、AniGen、SkinTokens、LegoACE 等,涵盖了动态分辨率、自动绑骨等多个前沿方向。
在应用层面,其一站式工作台 Tripo Studio 目前已聚集了 2000 万创作者,并与腾讯、网易、阿里、字节等头部企业建立了深度合作。
在 VAST 的技术蓝图中,世界模型与 3D 资产大模型并不是孤立的,而是“双轮驱动”的闭环。他们的长期愿景很明确:做“UGC 互动平台和 3D 内容生态的基座”。
在这个基座之上,无论是专业开发者还是普通创作者,未来或许都能以更低的门槛、更高的自由度去创造和探索可交互的数字世界。
神经网络引擎的成熟确实需要时间,但随着底层 3D 资产的充沛与解耦架构的跑通,一个数据驱动、可实时交互的数字空间,正在从概念走向现实。而 VAST 正在为此提供技术与生态层面的铺垫。
原创文章,作者:游茶妹儿,禁止转载:https://youxichaguan.com/archives/197507








